データ分析作業は以下の手順で進める。
 分析対象の量的把握と分析準備 分析対象の量的把握と分析準備
分析対象スコープとなるビジネスが持つデータ量を把握する。
分析作業計画
把握したデータ量と作業体制から作業計画を策定する。
○以下の4工程は、ユーザインターフェース毎に繰り返し実施
データ分類
ユーザインターフェース上のデータから分析対象を特定する。
エンティティの抽出
ユーザインターフェースのデータからエンティティを抽出する。
関連の設定
ユーザインターフェースのデータから関連を設定する。
属性整理
ユーザインターフェース上のデータをエンティティに割り付ける。
レビュー
ユーザインターフェース別のデータ分析結果をレビューする。
モデル統合
ユーザインターフェース毎に概念データモデルを段階的に統合する。
詳細分析
詳細なビジネスルールによる概念モデルの微調整。
モデル検証
エンティティとデータ項目の過不足を中心にモデルを検証する。
以下、手順を追って詳細に説明する。 |
なお、データ分析/データモデリングに関しては、株式会社エフ・エム・エスで、豊富な演習問題による実習を含んだ教育コースを用意しているので利用して欲しい。
また、データモデルのレビューや評価のみのサービスも提供可能なので、成果物の品質に自信が持てな場合や、ベンダーから納品されたデータモデルの検収が出来ない場合などに利用して欲しい。
データベース設計は、プロジェクトの早い段階で行われるが、その段階できちんと品質を評価しておかないと、データベースの品質が悪い事による決定的な影響が出るのは、試験・移行などデータの全体的な整合性が問われる、終盤の作業局面なので、リカバリーが難しい事が多い。 |
 |
 分析対象の量的把握と分析準備 分析対象の量的把握と分析準備
|
作業計画立案の基礎資料とするために分析対象を量的に把握する。
データ項目数とユーザインターフェースの種類別の数量把握は必須。
ユーザインターフェースのデザインや操作を確認するために必要となる、画面や設計書へのアクセスの容易性などの確認も行う。
なお、急ぐ場合や概要レベルでのデータ構造が分かれば良い場合などは、主要な入力ユーザインターフェスだけを選んで分析しても、8〜9割程度のエンティティ・データ項目を網羅しているので、ユーザインターフェースに入出力で区分をしておくと、計画立案時に計画策定の選択肢が広がる。
なお、分析対象の量的把握と並行して、以下の分析準備を行う。
・命名基準
データ項目の命名ルールを規定する。
・作図基準
既存の方法論や技法を採用する場合でも、技法の限界、作図ツールの違い、組織外の要員動員などで、いつものやり方や暗黙の了解が通用しない場合が多いので、分析方法た作図要領を基準として標準化する。
・教育コース
要員の大量動員が必要となる規模が想定されている場合は、初期教育のための教育コース(テキスト・演習問題・ツール操作要領・作業環境・指導要領など)を、目標水準に達したか否かの判定方法・講師などを含めて用意する。
・データモデルの管理環境
情報セキュリティの観点から、作業成果の保全と機密保持を図るため、本人確認とチェックイン・チェックアウト機能を持つライブラリ管理機能を設定する。
・指導レビュー体制
促成されたデータ分析者を大量動員によって稼働する場合、適時の指導と小さな単位での頻繁なレビューが欠かせない。
所定レベルの要員で、必要な指導レビュー体制を構築する。
・文書管理システム
成果物としてのデータモデルは前述の「データモデルの管理環境」で管理するが、作業に付帯的に発生する文書(例えば、データモデルレビュー評価表・指摘事項対応管理表・問題点管理表)など共用と履歴管理が必要な文書を管理するため、グループウェアなどの仕組みを用意する。
もちろん、既存の文書管理システムがある場合はそれを利用すれば良い。 |
|
分析作業計画
|
ユーザインターフェース毎のデータ分析を幾つか実施して、平均分析時間を把握し、全体の分析工数を見積もる。
工数は簡単な掛け算で求めることが出来る。
但し、データモデルを作業グループ単位と全体で、一つに集約する作業につては、ユーザインターフェース毎の分析作業と同じペースで進む訳が無いので、一律の見積は不可能である。
担当者が、経験と作業ボリュームから所要期間を設定するしかない。
また、既存要員のみで作業する場合は、所要期間は簡単な割り算となるが、納期短縮のために外部要員を動員する場合には、教育期間と指導・レビューの負荷を追加する事を忘れてはならない。
この段階で、作業体制と分析対象の割り当てを決め、進捗管理の指標も明確にする。
|
|
データ分類
|
例えば、データベースへの登録日時を記録として持つ事は当然だが、それは、データベースを運用・管理する上で必要なデータ項目であり、ビジネスの中で発生したデータではない。
また、当月売上合計金額などの集計項目は、売上として記録されたレコードの売上金額を期間で集計したデータなので、データ構造上で売上に入れる事は出来ない。
つまり、存在する全データ項目を、実装するためにDDLの大正とする物理モデルと違い、概念モデルにはデータモデルとして表現出来るデータ項目とデータモデル上では扱えないデータ項目がある。
これら、ビジネスのモデルとしては対象外となるViewデータや運用・管理データはあらかじめ分析対象外として分類しておく事が出来る。
もちろんデータ分析に習熟し、十分なスキルがあれば見ただけで対象外である事は自明なので問題ないが、特に、大規模作業で、促成の分析者を外部から動員しているようなケースでは作業を円滑にするめるためには必要な配慮である。
なお、分類されたデータ項目も一元管理するので、様式を決めて一元管理し、以後の重複発生を牽制する。
|
|
エンティティの抽出
|
識別子・ユーザインターフェースの名称・名称の接尾語(顧客名称など)などをヒントに,それぞれが示唆する対象をエンティティ候補とし、エンティティの存在を確認する。
エンティティの存在が確認された場合は、名称を付与しリソース・イベントの別を明らかにする。
名称には、基本的にビジネスの中でのエンティティの呼称となる。
通常、業務の中で意識していない存在が明らかとなり、ビジネスの中で呼称が存在しない場合は命名基準によって命名する。
また、エンティティにはインスタンスを識別する情報が存在するので、当該データ項目またはデータ項目群を識別子として特定する。
なお、リソースエンティティは、顧客に対する連絡先情報(電話番号やメールアドレスを複数持っている場合)や口座情報のように、識別子を共有または一部共有するものを集めてグループを形成し、図上は図の上方にグループ毎に配置する。
また、イベントエンティティは、前後関係から左から右へと後続イベントを連ねて配置する。
以上、エンティティの配置を識別容易となるように配慮して、企業毎の特性を配慮して標準配置を設定しておく事を勧める。 |
|
関連の設定
|
実は、関連を完全に理解する事は大変に難しい。
受講者の演習問題の出来栄えを見ていても、データ分析やデータモデリングを学習する中で、もっとも理解が難しい概念だと思う。
その証拠に、今まで見て来たデータモデルと称する図面に、如何に関連が少ないことか。
全く関連を持たないエンティティが表現されている位はまだましな方で、全く関連が表現されていないものを「ER図です」と見せられる事すらある。
と言う事で、ここでは、代表的な関連を例を使って説明するに止めたい。
 構成を表す関連 構成を表す関連
ビジネスは、存在する資源を組み合わせて、新しい行為・出来事を形成していく。
「顧客から商品を受注する」と言う具合だ。
ここで、受注は、ある顧客が、ある商品を注文すると言う概念なので、顧客と受注・商品と受注の間に、それぞれ関連が存在すると言う事になる。
また、イベントエンティティ(この場合は受注)に対して関連するリソースエンティティ(この例の場合は顧客と商品)が、多くの場合Who(誰が)・Whwre(何処で)・What(何を)として関連しているので、この関連を分かり易く分類するために「構成関係」と言う。
構成関係は、イベントエンティティの概念を説明するビジネスルールから把握可能である。
具体的には、イベントエンティティの入力ユーザインターフェースに、関連するエンティティの識別子の入力項目が存在する。
また冒頭の「顧客から商品を受注する」などとビジネスを規定する情報をビジネスルールと言う。
データモデルは、ビジネスルールを単純な表記法で図表に変換することで情報の集積度を高めることで、ビジネスの理解・把握を容易にしたものとも言える。
先行を表す関連
行為・出来事同士の先行関係を表す関連。
「受注した商品を配送する」と言うビジネスルールが存在する場合には、配送エンティティは先行するイベントエンティティである受注と関連があると言うことになる。
このようなイベントエンティティ間の関係を「先行関係」と言う。
ある意味で、構成関係のバリエーションだが、この関係を追う事で、ビジネスの骨格となる流れを追う事が出来る重要な関連なので、この関連を分かり易く、強調して表現すると分かりやすいデータモデルとなる。
従属を表す関連
良くある例では、受注と受注明細の関連。
受注明細は単独で存在する事はなく、受注の存在を前提としており、受注の識別子を持つ。
このように関連を辿って挿入された識別子を自らの識別子、又は識別子の一部とする場合、識別子を挿入する側に、挿入される側が従属していると言う。
これを「従属関係」と言う。
また、エンティティの中に不定の繰り返し構造がある場合、切り出して別エンティティとするが、切り出されたエンティティは、元エンティティの識別子を継承するので、この場合も元エンティティと切り出されたエンティティの関連を従属関係と言う。
以上の関連を押さえておけば9割方の関連は対応可能なはずだ。
後の詳細については、紙面で解説するのは困難なので、別に機会に譲りたい。
関連を設定したら、関連する二つのエンティティのインスタンス間の対応関係を多重度として明記する。
多重度の表現は表記法によって様々なので、自分たちの書き方を確認して欲しいが、表現の基本は、1件だけ対応するか、複数件対応するかだ。
例えば、顧客と受注の関係では、顧客側から見ると「一人の顧客は複数受注する」と言うビジネスルールなら、顧客一人に対する受注の多重度は「複数件多能する」となる。
逆に、受注側から見ると「1件の受注は必ず一人の顧客から行われる」と言うビジネスルールがあるなら、受注1件に対する顧客の多重度は「1件だけ対応する」となる。
これが重なって顧客と受注の関係の多重度は、1:n(ここで、1は1件だけ対応する事を表し、nは複数件多能する事を表現している)となる。
時々、A:Bの関係の多重度が1:nと言う事を、Aの1件にBのn件が対応しているとか、それぞれのエンティティのインスタンス数などと誤解している者が居る。
この場合の1はBの1件に対してAが1件対応する事を表す1であり、Bのn件に対応するAの1件を表している訳ではない。
1:1、n:nの関係で確認して見て貰いたい。
ここを疎かにしていると「複数のクラスに複数の学生が所属する」と言うビジネスモデルでクラスと学生の多重度を「エート、クラスも複数、学生も複数だからn:nか」などとしていまいかねない。
この多重度も、詳細については、紙面で解説するのは困難なので、別に機会に譲りたい。
ただ、基本的にビジネスのから捕捉されたエンティティに、関連の無いものは無いので、エンティティを抽出したら、必ず1本以上の関連を設定すること。
データモデルを言語に例えると(例えなくても現実に言語なのだが)エンティティは名詞や動詞に当たるが、名詞と動詞だけでは文章にはならない。
助詞や助動詞など、いわゆる「てにをは」を付けて文章として成立させ、ビジネスルールを表現するには、関連の設定が必須である。
|
|
属性整理
|
データの分類作業で、エンティティに配置すべきデータに分類されたデータ項目を、それぞれが帰属するエンティティに配置する。
この場合、導出項目は一律に実装すべきで無いとする考え方もあるが、既に、容量的制約は無くなっているので、一度導出しておけば値の変わる事が無いデータ項目については、遠慮無く実装して構わない。
本講座では導出データのこのような性質を指して再計算可能と表現している。
何度、再計算しても同じ値になると言う意味だが、何度、再計算しても同じ値になるのだから、一度計算した値を保持しておけば再計算の手間がなくて良いと言う考え方だ。
これに対して、導出を実行する度に、値が変わる可能性があるデータ項目を再計算不能と表現している。
例えば、取引先の債権残金額は、受注や入金の都度、値が増減する。
このデータ項目は元よりViewなので、事実を記録している取引先エンティティに属性として加える事は無いが、取引先を単位とするデータ項目としては、何れかに定義しなければならない。
その時に、値として実装し、関連イベントが記録される都度、再計算して値を更新しておくか、導出ルールの定義のみで値は実装せず、データ要求時に導出プログラムによって、その都度計算して値を提供するかは、計算負荷とデータ項目の利用頻度によって検討することになる。
間違っても、これらView項目をビジネスの事実を記録している部分に混入してはならない。
不要な更新を誘発することで、データベースの安定を損なう事になる。
なお、データ分類からエンティティの抽出・関連の設定・属性整理を通しての、いわゆるデータ分析作業に関して、把握すべき事、理解すべき事などを整理するために、普段使っており、使い方に精通し、その技法やツールを利用すると作業がはかどるようなもの(例えばDFD・UMLのある種のダイアグラム・プロセスフロー図・DMMなど)があれば、大いに利用すべきであるが、分析後の成果は基本的に全てデータモデル(とリポジトリなどのデータ項目毎の定義やルールを記録する補助機能)に収斂するので、作業途上で利用した中間生成物は保管・更新の対象にはしない。 |
|
レビュー
|
ユーザインターフェース毎の概念データモデルは、断片的なので、ビジネスの流れやビジネスルールを読み取ったり検証する事は難しい。
それらのレビューは少なくとも、業務別、商品別など、ある程度モデルのインテグレートが進んだ段階で、データ分析に対して情報や資料を提供した業務の精通者を交えて行う事になる。
しかし、多くの要員を、データ分析者として促成で作業に当たらせている場合など、思わぬ思い違いや誤解がある可能性が考えられる。
それら誤解や思い違いの早期発見と、作業の生産性向上に向けた、再教育・追加教育内容の把握のために、ユーザインターフェース毎のデータモデル完成の都度、レビューを行う。
レビューは、作業の手順や表現形式の遵守性を中心に行うが、明らかにビジネスモデルやビジネスルールとして不自然なものについては当然指摘して構わない。
また、レビューは対面で行い、指摘事項についてその場で指摘し説明をくわえても良いし、非対面でデータモデルの内容を確認し「概念データモデルレビュー指摘事項一覧」のようなドキュメントにして、担当者に指摘事項を伝達しても良い。
経験的に言うと、当初は対面でレビューを行い、有る程度ミスがパターン化する段階で、頻発している指摘事項をあらかじめ設定した文書での結果伝達に変えるとレビュー工数の節約になる。
もちろん「概念データモデルレビュー指摘事項一覧」の指摘で同じミスが改善されないようなら、対面の個別指導を適宜行う。 |
|
モデル統合
|
ユーザインターフェース毎などの作業単位で、レビューを完了した概念データモデルは、機能や商品などのモデル統合単位に、統合担当者の下に集められる。
モデル統合担当者は、集まった概念データモデルを統合するが、ここでもイベントエンティティの登録業務を優先して作業すると、関連するリソースやイベントの前後関係などを把握し易いので、全体の配置やバランスを考慮した作業が出来る。
リソースエンティティの登録業務だと、リソースエンティティの箱を一つずつ描くことになるので、全体のレイアウトが決まってからにした法が無難だろう。
作図基準のレイアウトの遵守事項として、図全体のレイアウトの要領も規定しておき、この段階から適用しておけば、最終的な全体統合時に余計な手間が省けるだろう。
如何にレイアウトすると見易いかと言う事に関しては、表現の技法や使用するツールによって違って来るので、各自の環境で検討して貰いたい。
なお、モデル統合後の元のデータモデルは廃棄して良い。
以降の変更・修正は統合モデルを直接直すので、中間生成物としてのユーザインターフェース毎のデータモデルを持っていなければならない理由は無い。
また、データモデルに反映されないデータ項目に関しても、名称・定義・ルールなどを統合管理情報に移管すれば個別に情報をもっておく必要は無い。
と言う訳で、この辺りの作業段階から、共用データを一元的に記録し、チェックアウト・チェックインと変更履歴を管理する仕組みが必要となる。
もちろんソフトウェアー製品を導入しなければならない訳では無く、仕組みとして確立されていれば良いので、規模的に運営上の問題が無ければ、登録申請書や貸出管理台帳での運用で構わない。
蛇足ながら、リポジトリなどのソフトウェアー製品の機能は、一般的にヘビーユーザの要求に答えようとして盛りだくさんになっている。
開発者が豊富な機能を売り物にしようと、専門家やヘビーユーザに要件を確認して開発するのだから当然だ。
しかし、多くの場合、それら機能の大部分は使う事がない。
世の中にはプロ用とかプロ機と称するものが存在し、その多くに、一般機・汎用機にはないスイッチやつまみが付いている。
つまり、プロとして活動していくためには、それらスイッチやつまみの機能による差別化が必要だと言う事だが、最初はみんな素人だ。
普通は、素人には素人に相応しい器材が存在するものだ。
スイッチやつまみの数を見れば分かる。
ソフトウェアー製品も必要に応じて使い分けて行けば良いので、良く分からないままに、高価な製品を買ってしまったなどと言う事にならないように気を付けたい。
分からなければ、最初は必要な項目を表計算ソフトで管理するだけで十分である。
本来、合理化省力化が目的のビジネスシステムで、使えもしない無駄な買い物をしていたのでは「何のこっちゃ」である。
なお、モデル統合は、当然ながら、作業単位毎の統合を経て、全体の統合へと進む。
スコープが大きな場合は、数段階に分けて統合作業を進める方が効率が良いような気がするかも知れないが、既存システムのファイルやデータ項目の多寡に依らず、エンティティが5〜6百、データ項目は2千項目程度(改めて言うが、View系の導出項目はここで言うデータモデルを工税するデータ項目ではない)に整理されるので作業単位毎のレビューが正しく行われていれば、第二段階で全体統合を行う事に無理はない。
逆に、手に負えないほどの量のエンティティやデータ項目があると言う事は、名称の統一やデータ分類などが有効に行われていない可能性が大きいので、レビュー段階では、それらの対応状況についても確認しておく必要がある。
また、全体図が出来たら、中間のデータモデルは廃棄し、以降の変更・修正は直接全体図に反映する。
それに伴って、変更の申請から承認・作業内容確認までの一連の手続きを明確にしておく必要がある。
この手続きは、データベースの初期創生からデータ移行やテストを経て、運用/保守(最近は保守の表現は敬遠され、「拡張開発」とか「エンハンス」と呼ぶのが流行りのようだ)になってもそのまま使う仕組みなので、プロジェクトに従属した運営から、全社レベルの変更対応業務へと円滑に移行出来るように、事前に検討しておく必要がある。
極端な話、委託先別、プロジェクト別に申請書を変えていたのでは堪らない。
プロジェクトに投入された要員は余裕が無くなるものなので、全社レベルのマネジメントシステムとして業務要件の変更申請から、データモデルの変更、データベースの変更、変更の開示公表に至る一連の手続きを、予め十分に検討しておくべきであろう。 |
|
詳細分析
|
詳細分析とは、詳細な分析である。
例えば、商品の価格として、商品価格と得意先別商品価格が存在した場合を考えて見る。
通常、商品価格は商品の属性なので、商品エンティティに入れれば良い。
ところが、得意先別と修飾されているので、このデータ項目は、得意先と商品の両方に従属している必要があるので、商品エンティティに入れて済ます訳には行かない。
もし、この段階までに設定されていなければ、得意先と商品の両方に関係を持つ(両方の識別子を継承する)エンティティを設け、そこの得意先別商品価格を入れる。
また、価格が商品価格と得意先別商品価格に分かれると言う事は、一般の取引先と得意先で取引金額の計算式が異なる事を意味するので、名称も同じと言う訳には行かない。
一般の取引先が金額なら、他方は得意先金額とでもするべきだろう。
導出ルールが違っているにも関わらず、同じ名前を使っていては、分かり難いと言う以上に、使い分け条件を一々説明する必要があり、プロセスに負担を掛ける事に留意しなけらばならない。
後で説明を加えれば良いと言うものではない。
後続作業全体の使い易さや誤解・思い違いのリスクを考えれば、何れが優れたやり方か、迷う必要もないだろう。
また、金額導出の使い分けが発生するので、イベント自体もサブセットに分割される。
該当のイベントエンティティが受注であれば、一般受注と得意先受注と言う訳だ。
また、当然ながら、取引先に一般と得意先の区分が存在する事も明らかなので、得意先もサブセット化され、一般と得意先に分割される。
分かり難いので図で示す。
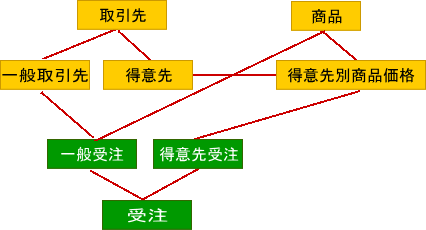
このモデルを受けて、受注登録のアプリケーションは、先ず、受注には一般受注と得意先受注があるので、どちらか判断が必要だと言う事が分かる。
そこで、得意先別商品価格に得意先の識別子と商品の識別子が存在する事を確認する必要があるので、取引先の識別子と商品の識別子が入力された段階で、得意先別商品価格をアクセスし、どちらのサブセットかを特定すると言う仕様が自明となる。
以上、詳細分析の中心となるサブセットについて例示した。
サブセットは日本語では分類構造、クラス図ではサブクラスと言われる概念だが、要するに、一つの概念だと思っているが、その中にちょっとした違う違いがあるものが混ざっている状況を示す表現だ。
これを綺麗に表現出来るとモデルの表現力が数段向上する。
逆に言うと、分類構造が詳細に表現できていないと概要レベルのレイアウトでしかない。
分類構造を表現する切っ掛けは、主に、既存システムのイベント系マスタに多く含まれている、区分・種別・フラグなどの情報だ。
それごとに、エンティティの何が違っている事を表そうとしている区分・種別・フラグなのかを分析して行く。
詳細分析の要素は、分類構造の他にも、明細構造・再帰構造・関連センティティなどがあるが、分析のポイントは、ビジネスで認識しているエンティティに記録されるインスタンスの性質の画一性だ。
少なくとも、システム内の扱いが同じものをエンティティに集めているはずなので、このデータは先ず〜区分で判定してなどと言うデータをまとめているようだと、分類構造での整理を検討する必要がある。
また、逆に気持ちが先行して意味の無い分類をしてアプリケーションに無用の負荷を掛けているケースも考えられるので要注意だ。
これは、リソース側が分類構造となっているだけで、それを受けるイベント側がスーパーセット側としか関連していない様な場合、つまり分かれた側での関連が設定されていない様な場合が当たる。
将来を見越して、設定した区分やフラグが意味も無く設定され続けているか一向に使われないと言う事も、レイアウト単位でデータを読み書きしていた時代の遺物である、必要なデータ項目は必要な時点からカラム単位で追加・変更・削除が可能となっているので、これをうまく使わない理由は何もない。 |
|
モデル検証
|
さて、データ分析手順の最後はモデルの検証だ。
最終的に全体を統合して一枚のデータモデルにまとめ、詳細分析で得たビジネスルールも反映したものを検証する訳だ。
この作業自体はモデル統合時のモデル検証と言う位置づけなので、各作業単位での統合作業も全体の統合作業も同様に検証可能だ。
全体の配置
・リソースについては、グループが明確か、イベントについては、流れが読み取れるか
・属性の多いエンティティは無いか
・関連の無いエンティティは無いか(こんな事をチェックしなければならなう様だとちょっと情けない)
など
エンティティ
・識別子は明確か
・関連キーは明確か
・属性に初期値設定をするものはないか
・属性に値がNullになるものはないか
・ただのコード表をエンティティ扱いしていないか(但し、描画ルールによる)
など
関連
これは一目見て、判断出来る要素は少なく、如何に示す外形的な不備程度だ。
・多重度の記述はあるか
・関連による識別子の挿入方向は正しいか
予断だが、ここで識別子の挿入方向の意味が分からなかった者はデータベースの設計を云々する資格は無い。
関連は、存在から行為・出来事へ、先行する行為・出来事から後続する行為・出来事へと、何が組み合わされて何になるのかと言う、ビジネスルール上の明快な方向性があり、それに逆行する識別子の挿入は無い。
そのため、1:nの関係では1側の識別子をn側に挿入するものと思い込んでいる者もデータベースの設計を云々する資格は無い。
その理屈が理解で理解出来ていない者は、すぐにFMSのセミナーに申込なさい。
・ただのコード変換を関連として扱っていないか(但し、描画ルールによる)
属性
・属性に重複は無いか
・Wive系の導出項目を属性に置いていないか
・その逆は無いか
・同じデータ項目を別名で重複させていないか(当月〜・前月〜・全前月〜・3カ月前〜・・・・など)
・無用の更新を誘発するデータ項目を安定した構造に混入していないか
など
簡単な例だけを示した。
ビジネスルールを全て含んでいるので、ビジネスルールの意味内容面からの確認も行うようにして欲しい。
多分、作成者側がモデルをビジネスルールに翻訳して業務部門の情報提供者に説明する形式を想定しているのだろうが、もともと簡単な事が取りえの表記法だ。
簡単で、文章に書く様な、裏の意味とか含みとか思い入れとかが書けない事が良い所なので、データ分析を行ってモデルを作る事は難しくても、読んで、情報を共有するだけなら大した訓練は不要だ。
今後の情報共有(何しろ、データベース導入後のビジネスルールの維持は、今までの様に、曖昧な設計書や人の頭脳ではなく、データモデルとリポジトリで管理されるのだから)を前提にすれば、業務部門の主要なキーマンにも読み方を習得させる事が無駄にまる事は無いので、一度チャレンジしてみてはどうか。
チャレンジして失敗したらどうするかだと。
もう一度チャレンジするに決まっておる。
|
データ分析に手順に関する説明は以上だ。
汎用的に通用する考え方のポイントを中心に解説した積りだが、何しろ世の中は多様なので、ここでの指導が適切でない場合も考えられる。
と言う訳で教条的な利用は(生兵法は)怪我の元なので、自分が理解し納得出来る範囲で活用して欲しい。
世の中は教条的な分析で足りるほど、簡単な造りにはなっていないと言う事だが、日々知恵の限りを尽くして工夫と創造を重ねているビジネスにおいては尚更である。 |
|
 お疲れ! お疲れ!
|
取りあえずここまで読んだと言う事は、何某かの知識が得られた事と思う。
知識が得られないまでも、少なからず疑問は湧いた筈だ。
現在のビジネスシステム開発プロジェクトに於いては、データベースの設計品質がプロジェクトの成否を決定する。
よって、プロジェクトの成功を期するためには、データベース設計スキルの修得は不可欠だ。
しかし、残念ながら十分なスキルが無いまま、いや、データベースと従来のファイルの違いすら理解しないまま、無謀にも巨大プロジェクトのデータベース設計に安易に取り組むプロジェクトは多い。
もちろん頓挫するのだが、情けない事に彼らには、その理由すら理解出来ない場合が多い。
孫子の形編第二節に「勝ちを見ること、衆人の知る所に過ぎざるは、善の善なる者に非ざるなり」と言う件がある。
岩波文庫の孫子(金谷治訳注)では「勝利を読み取るのに一般の人々にも分かる〔ようなはっきりしたものについて知る〕ていどでは、最高にすぐれたものではない」と注釈している。
システム開発プロジェクトでは、勝ち(プロジェクトの成功)を見るのなら、衆人の知る所に過ぎなくても何の問題も無いが、負け(プロジェクトの失敗)に関しては、他の誰よりも早く、その予兆を察知して、予兆のままに解決する必要がある。
即ち、予兆の内に問題の発生を察知し、顕在化する前にすでに解決しているので、善の善なる者(有能なプロジェクトマネージャー)は常に平穏なプロジェクト運営をしている様に見え、顕在化してしまった問題を、如何に工夫して解決したかと言う手柄話や、どんな努力で乗り切ったと言う苦労話とも無縁なので、却って賞賛や尊敬の対象となる事も無いと言う事だ。
賞賛や尊敬の対象となる事が無いのはちょっと残念な気もするが、その判断の中核となるのが、データベース設計の品質に他ならない。
つまり、現在のビジネスシステム開発プロジェクトに於いて、善の善なるプロジェクトマネージャたるのは、データベース設計の能力とは言わないまでも、データベース設計の能力を見抜く能力位は不可欠だと言う事だ。
同様に、委託者責任が常識化しつつある今、「委託先が失敗しました」で済むと思っているユーザ側の責任者が居るとも思えないが、予算とプログラムの完成本数を勘定しているだけでは、効果的な委託先管理とは言えまい。
既に、半年先の破綻が、データベース設計の中に仕込まれているかも知れないのだ。
ここでも、データベース設計の能力とは言わないまでも、データベース設計の能力を見抜く能力位は不可欠だと言う事だ。
納品された概念モデルを見ないまま放置し、検収依頼に確認印だけ押すなどと言う事があってはならない。
分かりやすい事もあり、下流の実装工程の議論は、相変わらず盛んだが、データベースの品質有ればこその話である。
第一、気の利いた開発者なら、造りのおかしなデーテベースに疑問を持たない筈は無い。
ここでも、データベース利用者側からの評価の目が必要である事は言うまでも無い。
つまり、多くのシステム関係者にとって、データベース設計は「設計担当者がやれば良い」問題では無いのである。
君が、あなたが、私が、僕が、データベース設計を知らない事が、プロジェクトを失敗へと誘導していたとしたら、もう、データベース設計スキルの習得に躊躇も迷いもあるはずは無いし、経営者・管理者はそれを勧める以外に無いだろう。
失敗に原因があるように、成功にも原因がある。
このサイトが、諸君の次回プロジェクト成功の切っ掛けに成れば望外の喜びである。 |